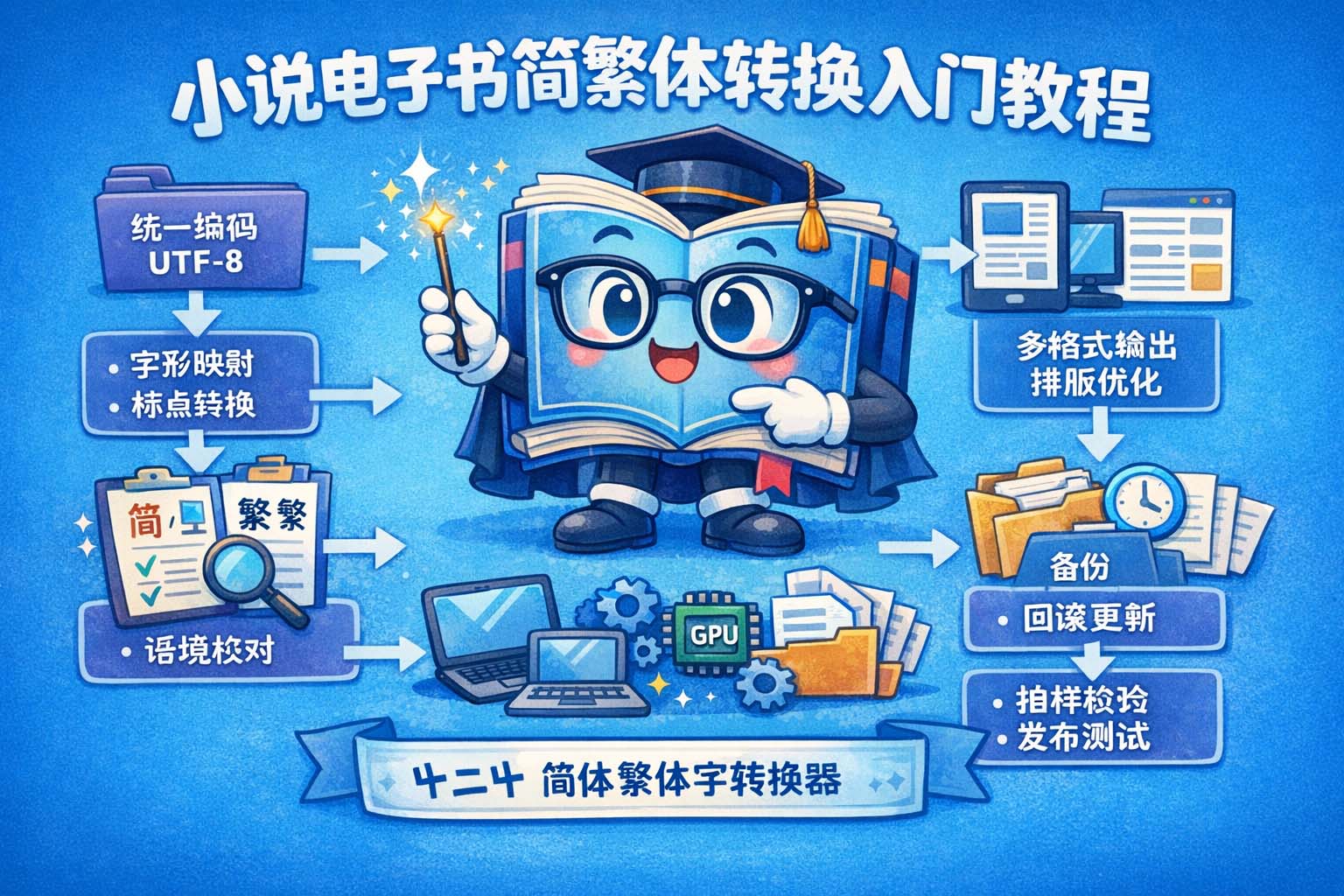
本教程以“小说电子书简繁体转换入门教程”为主线,面向刚接触电子书文本处理与排版的人士,系统讲解从编码规范、字形映射、语境判别到排版恢复与质量保障的完整流程。文中不涉及任何具体软件品牌或产品,而是着重说明底层逻辑与可复用的分步解决方案,便于在不同场景中落地实践。
电子书文件常见编码为 UTF-8,但仍有遗留 GB、Big5、或带 BOM 的文本。底层逻辑是:错误的编码会导致字节被错误解析,进而产生乱码或错字符。因此第一步必须统一编码到 UTF-8,并规范换行符(LF/CRLF)与空白字符。
简体与繁体不仅是字形差异,还包含标点、数字格式、专有名词书写习惯等差别。确定目标读者(大陆、台湾、香港、海外华人)有助决定标点样式、书名号与引号等排版策略。
不少字符并非一对一映射——存在多对一、异体字、兼容字问题(例如“后/後”在不同语境下含义不同)。底层逻辑是:单纯字符替换会引入语义错误,必须结合上下文或使用白名单/黑名单策略处理专有名词与人名。
标点在排版与阅读节奏上起关键作用。转换流程里应把标点映射和字形映射分开执行,并在输出阶段统一规范化全角或半角的使用,以保证页面换行、对齐和首行缩进不被破坏。
将“内容(文本)”与“样式(排版)”分离可以减少转换引发的版面问题:先处理纯文本的编码和字形,再在保留排版标记(如段落、章节分隔符、特殊缩进)的前提下恢复样式。
备份原始文件;统一编码为 UTF-8;去除不可见控制字符与多余 BOM;统一换行与空白。对 OCR 得到的扫描文本,先进行错误修正和段落重建。
准备基础简→繁、繁→简映射表,并辅以专有名词白名单(保留原写法)与黑名单(禁止自动替换)。映射表应支持多级优先级:用户词库 > 专有词库 > 通用映射。
对多义字符建立上下文规则,例如通过前后字、标点或句法提示判断正确映射;使用正则处理常见模式(书名、注释、诗歌断行)以避免误替换。
针对批量电子书,设计流水线:编码统一 → 预处理 → 映射转换 → 语境校验 → 排版恢复 → 输出分发。设定抽样率(如每 20 本抽检 1 本)和自动生成差异报告,便于人工复核高风险片段。
恢复章节标记、首行缩进与对齐规则;在输出 HTML/EPUB/文本时,使用样式表(CSS)保持断行与缩进一致。对于需要直排或特殊版式的文本,保留源文件中的特殊标记并单独处理。
在目标设备(主流阅读器或浏览器)上进行页面预览和分页测试;记录每次批量处理的变更日志以支持回滚;对后续更新采用增量策略,只处理变更部分,减少重复风险。
优先做段落重建与常见字符纠错(例如把 O 与 0、l 与 1 的误识别按上下文修正),之后再做简繁转换,避免在错误文本上放大映射错误。
对话常有破折号、引号和不同缩进规则,诗歌需保留断行。建议采用标记化方法把这些结构暂时“隔离”起来进行转换,最后再合并回原排版位置。
建立专门术语库与人名库,配合模糊匹配与人工审核来保证一致性。对于频繁出现但容易冲突的词汇,可采用“首次出现提示”机制供人工确认。
结合抽样检查与规则触发检查(低置信度替换或高频变更),把可疑区域汇总到审核列表,优先处理错漏率高的章节与人物名称。
在大规模并发处理时,关注三类资源瓶颈:CPU(文本处理、正则)、内存(映射表与缓存)和 IO(读写文件)。底层优化策略包括:共享只读字典到内存、为每个任务使用独立临时目录减少锁竞争、使用作业队列控制并发度、并把耗时的渲染或封面生成任务拆到专门队列执行。
事实是这会带来大量语境错误。正确做法是分层替换并结合上下文判别与人工抽检。
出版发布关注的还有标点、排版与设备兼容性,必须把这些环节纳入流水线。
“小说电子书简繁体转换入门教程”既是技术流程也是质量管理工程。掌握编码规范、建立分级映射与语境规则、结合自动化检测与人工审核,并在批量场景下做资源隔离与并发控制,才能在保证文字准确性的同时实现高效可复用的转换流程。遵循本文分步方案,你可以在不同场景下稳步搭建出适合自己需要的转换流水线,获得良好的阅读体验和可控的发布质量。
参考文章:小说编辑简体繁体字转换
上一篇: 如何用虚拟桌面实现工作娱乐完全隔离?
下一篇: 文本文档简繁体互转常见问题解决方案
Copyright © 2023 - 2033 b2bangong.com All Rights Reserved.
